
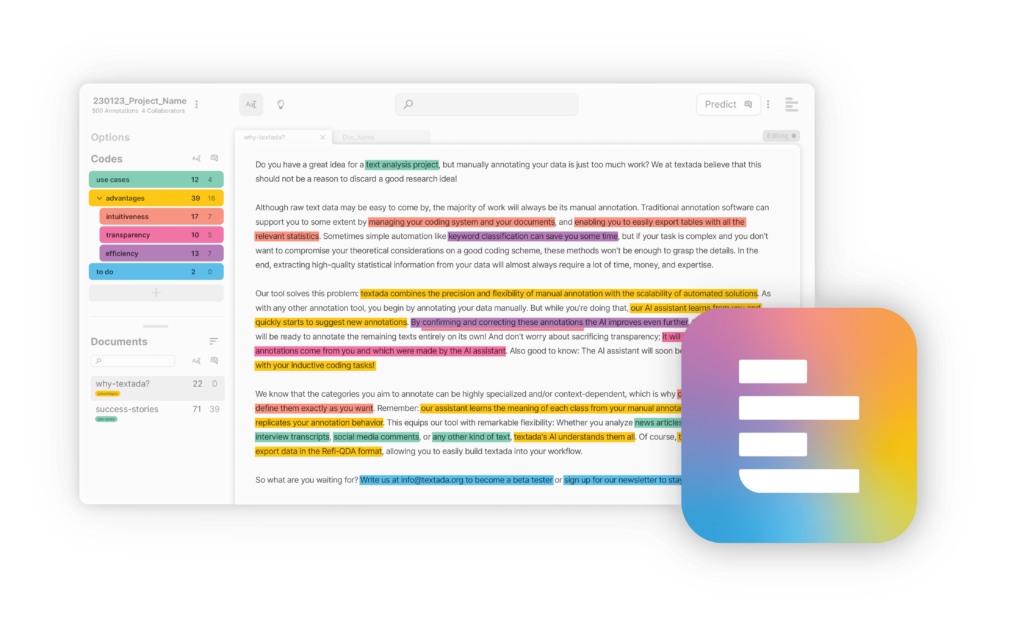
Artificial intelligence has transformed the way language models are trained, yet the foundation of these systems rests on how data is prepared. Text annotation serves as a bridge between raw information and structured datasets, which allows models to capture linguistic nuances. With AI-driven annotation, this process achieves a level of speed, scale, and precision that manual methods cannot match.
The growing demand for large language models across industries highlights the importance of data that reflects varied contexts. Annotated datasets provide the groundwork for accurate comprehension, reasoning, and generation of text. As models expand into new domains, text annotation AI ensures that they are not limited by human bandwidth or inconsistencies.
Table of Contents
It Enhances Accuracy in Labeling
High-quality datasets require precision in identifying entities, relationships, and sentiment. AI-driven annotation reduces the chance of human error, which often arises from fatigue or subjective interpretation. This leads to labels that are consistent across millions of samples, which creates reliable training inputs. Accuracy in annotation also ensures that rare linguistic structures and complex phrases are captured. Such refinement strengthens the ability of large language models to generalize and perform effectively across tasks.
Scales Data Preparation Efficiently
- AI tools can process thousands of documents simultaneously, which enables large-scale annotation without sacrificing quality.
- This scalability is vital for domains where continuous updates are required, such as healthcare, finance, and customer support.
- Automation accelerates dataset preparation to ensure faster development cycles for language models.
Scalability also makes it possible to create diverse datasets across multiple languages and cultures. Without such systems, preparing broad, representative corpora would be a resource-heavy challenge.
Supports Multilingual Diversity
Language models must understand more than one dominant language to serve a global audience. AI-driven annotation enables the consistent handling of multilingual text, which includes complex scripts and regional dialects. Such capability is essential for building inclusive datasets that capture linguistic richness. With automated systems, annotation can extend beyond simple translations. It incorporates cultural context, colloquial expressions, and idiomatic usage, all of which strengthen the performance of multilingual LLMs.
Helps in Domain-Specific Training
- Industries require tailored datasets that reflect their specialized vocabulary and structure.
- Text annotation with AI helps categorize and tag data from legal, medical, or technical sources with domain-specific accuracy.
- This allows LLMs to generate responses that are both context-aware and reliable in professional environments.
Such domain-focused preparation ensures that models are not confined to generic language use. Instead, they gain the expertise to function effectively in high-stakes applications.
Improves Dataset Quality with Feedback Loops
AI systems can integrate continuous feedback from model outputs into the annotation cycle. This iterative approach highlights mislabeled data or ambiguous cases and refines them over time. As a result, datasets become more balanced and robust. Quality improvements from these loops reduce bias and strengthen fairness across different demographic groups. This ensures that LLMs perform equitably, which reflects diverse user needs.
Reduces Time and Resource Costs
Manual annotation demands large teams and extended timelines, which increase project costs. AI-driven annotation tools cut down these requirements significantly, which allows smaller teams to achieve broader results. This shift makes the creation of advanced datasets more accessible for research groups and enterprises. Lowering costs also frees resources for additional innovation. Teams thus can focus on designing better models rather than managing repetitive labeling tasks.
Hence, AI-driven text annotation is central to shaping diverse and powerful LLM datasets. It enhances quality, reduces inefficiencies, and supports inclusivity across languages and domains. As language models continue to expand, AI-supported annotation will remain the backbone of their success.